理性与博弈论
引言
如果你得到一千元,不附带任何条件,你可能会拿钱,然后跑走?如果金额不是一千元,而是一万元,不附带任何条件,你可能会拿钱,而且跑得更快。但是,如果你在大街上看到一张100元的钞票,而你最近背部已经疼痛难忍,虽然当时你的痛苦减轻了很多,但你可能不会弯腰把它捡起来。当然,对一毛硬币更不值得弯腰。经济学家和数学家在解释有关经济行为并提供建议时,会调用“理性”行为的论据来解释人们应该采取什么样的行动。然而,正如上面的例子所显示的,如果决策者比观察者有更多的信息(比如背部状态),那么观察到的行为和可预期的行为可能不一样。
 |
 |
| 冯·诺伊曼 | 摩根斯特恩 |
由数学家约翰·冯·诺伊曼(1903-1957)和经济学家奥斯卡·摩根斯特恩(1902-1977)首创的博弈论,提供了许多发人深省的例子,其中逻辑上行得通的行为与实际上看到的行为之间的区别有着天壤之别。因此,博弈论提供了数学家、心理学家、政治学家、哲学家、经济学家和其他学者一个令人兴奋的舞台,来探索位于他们各自学科核心处的迷人思想并获得探测各种各样的问题的工具。如果以数学建模的角度来看博弈论,其中博弈论的部分用来提供“现实世界”中的行为表示,则涉及博弈的试验不仅提供了改善我们对人类行为洞察力的方式,而且对博弈论本身也开发出新的方法和思路。
那些熟悉博弈论的读者,可以只略读下一节,它是关于博弈论的一些比较出名的方面。这个预备材料的目的是对某些博弈进行“标准”博弈理论和实际操作之间的对比。
博弈论的基础知识
博弈论已经发展成为一个复杂而多分支的学科。其基本思想是:有一群人(通常被称为玩家)相互交融,并存在他们希望解决的一些冲突。为了简单起见,让我们考虑只有两个人(国家或企业)的玩家。根据由玩家采取的行动或决策,对所涉及的两个人将产生不同的“回报”。我们假设,该游戏是具有完美信息的博弈。这意味着,每个玩家确切地知道他及其对手采取什么行为。我们还假定每个玩家的回报以及它们的值都是已知的。这里我们感兴趣的游戏通常出现在日常生活、经济和政治科学中,而与如Nim,Dots,Boxes及Hackenbush这样的组合游戏相反。下面的例子给出冲突情形可用博弈论阐述的一些范围:
- 情形 1:丈夫和妻子正试图决定星期五晚上做什么,丈夫喜欢看电影,但妻子想去看歌剧。
- 情形 2:X国以测试新开发的地下核武器相威胁,Y国对此可能性感到不安。
- 情形 3:两个孩子同时闪动一个手指或两个手指。如果总和是偶数,每个孩子赢得一毛钱;如果总和是奇数,每个孩子则失去一毛钱。
- 情形 4:两个相互竞争的的电子商店必须决定在感恩节前一周是否使用电视广告。
这些小样品的情况显示涉及到当事者的不同程度的后果严重性;虽然只提到两个人(实体),其他的“当事人”经常受他们在博弈中所作决定的影响。例如,在核试验的情形,如果地下核试验出了问题,整个世界则面临核辐射排放到大气中的危险。
这些种类的情形可能只发生一次,也许在或多或少相同的情况下多次重复。有时玩家可能会互相沟通采取行动,但在其他情况下他们的行动或多或少彼此独立。即使玩家可以沟通并达成协议如何竞争,但也不总能保证单方或双方不会违背已经同意的“条约”。有时玩家可能彼此是陌生人,而在其他情况下,他们可能彼此认识。当玩家确实知道对方时,他们可能知道各自的值会是多少以及他们在游戏不同情形下的思维方式。然而,即便对方是一个陌生人,玩家们对公平性、同情和利他主义等的看法可以左右他们的行动。
当玩家在这类游戏中互动时,他们可以复杂的方式通过游戏玩法注视其结果。在一些游戏中,有转手于玩家之间的金钱,然而在许多情况下,结果可以用多种尺度衡量。因此,上面那对夫妇决定星期五晚上干什么时,其结果可能会受金钱影响(电影通常比歌剧便宜),但也有“满意度”的结果。心理学家和经济学家,加上数学家,已经开发出一种“效用”理论,该理论试图允许获得某个结果的游戏(或者更一般地,做出某个决定)玩家指定一个被称为效用的数。主要的想法是,如果行动A优选于行动B,则指定给A的效用应该高于指定给B的效用。但是众所周知,在表达优先方面人们并不总是一致的。因此,约翰在苹果和香蕉中可能更喜欢苹果,在香蕉和樱桃之间更偏向香蕉,碰到樱桃和苹果时则宁愿樱桃。当这种优先关系的“非传递性”被指出时,有些人会“纠正”其既定的偏好,而其他人则坚持他们的初衷。这可能是因为该人缺乏一个单一的基本尺度据此判断水果,而这就意味着表达偏好时,一个人如何平衡对水果的复杂观念。因此,当存在这样的“循环”偏好时,不可能对每种水果指定一个数,使得指定数较高的水果优于指定数较低的。
这个简短的讨论表明,“效用理论”是一个迷人和复杂的主题。因此,一个富人和一个穷人对游戏中易手的同一笔钱可能有完全不同的想法。出于我们的目的,让我们假装玩家都能自己评估如何借助某些尺度来衡量本场游戏的结果。游戏中出现的这些结果来自于玩家在可取行动之间做出的选择。每个玩家的一个行动导致一个结果。有时玩家会知道与某个结果相关的效用,但有时他们不知。我们还假设,给出高与低的回报选择时,双方玩家总是会选择较高的回报。
为方便起见,我们将游戏中的两个玩家称为甲和乙。我对甲用女性代词,对乙则用男性代词。我们怎样才能记录游戏中可供玩家采取的行动?一种方法是使用一个“树形图”,其中树的顶点(有时也被称为节点)显示玩家的可取选择,其举动在此节点表示。在最简单的情况下,这些树图只是显示为玩家的行动方案,但它们也可以用来显示,在不时的可能选择下,什么样的信息可以提供给玩家。因此,一个玩家的对手可能会知道或可能不回知道对手在一个树图节点可能采取什么样的选择。当游戏的“移动”和回报以这种形式显示时,该游戏被描绘为具有“扩展型”。一个很简单的例子如下(图1)显示。在图中,树的1价顶点,或树的叶子,标有(r,c),表示甲和乙的回报。因此,如果甲采取她的选择II而乙用他的选择1,则甲失去8元,即乙得到8元。这可被解释为意指甲支付乙8元。
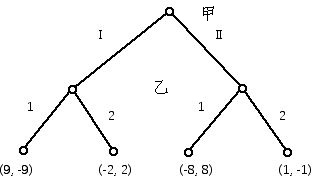 图1
图1 如果结果以“正常形式”显示,这个游戏的“扩展型”可以显示得更紧凑,并在许多方面更为清楚(尽管前面提到的一般性会损失)。这可以通过一个矩阵表示,该矩阵的行显示甲的选择,列则代表乙的选择,如图2那样。他们的回报再次以一对数表示,每对中的第一个分量是玩家甲的回报。这个游戏的玩法是:彼此没有沟通的两个玩家各自选择两个行动之一。对甲而言,这意味着选取行I或行II,而对乙则表示选择第1列或第2列。你能把每个玩家视为甲在一张纸上写I或II,乙在一张纸上写1或2,再交给一个法官。然后这位人士确认所涉及的回报。例如,如果甲写II而乙写1,则法官让甲给乙8元。这种特殊的游戏被称为零和游戏,因为游戏每一次玩后的转手金钱的总和是零。(通常在一个零和游戏的矩阵的每个单元格中只显示一个回报数目。这个数字通常是以行代表的玩家的回报。以列代表的玩家的回报可以推断为前者回报(可为负数)的相反数。)
| 乙 1 | 乙 2 | |
|---|---|---|
| 甲 I | (9, -9) | (-2, 2) |
| 甲 II | (-8, 8) | (1,-1) |
假设你一遍又一遍地玩这个游戏。这意味着你(比如说你就是甲)在玩第一轮时必须选择I或II,然后根据乙在你之前玩的招数或与他跟随的任何行为独立地决定你下面的每次行动。你会选择如何玩呢?注意到回报的对称性表明,对于甲而言最好的事情同时对乙而言也是最糟糕的。也请注意,玩家甲的所有项(可能的结果)加起来为零。你认为这意味着该游戏“公平”吗?公平的游戏可被认为是这样的,假如这两名玩家各自尽可能地玩好(如最佳玩法),长期玩下去则有净回报为零的结果。
混合策略
倘若你是甲的话,也许你不很清楚什么是图2游戏的最佳方案。下面的游戏或许更简单一些!
| 乙 1 | 乙 2 | |
|---|---|---|
| 甲 I | (9, -9) | (-2, 2) |
| 甲 II | (4, -4) | (-5, 5) |
如果你是甲,你会怎么玩这个游戏?注意,因为9比4大,-2也大于-5,如果甲起用行I,无论乙做什么,甲都将得到更高的回报。因此,鉴于在我们的讨论中更多的钱优于更少的钱,甲从来不会玩行II,因为无论乙做什么,她玩行I都可以做的更好。在这样的情况下,我们说行I主导行II,因为无论乙选哪一列,甲选行I得到的回报都比选行II好。但是,如果乙是一个理性的玩家,他会知道甲永远不会选行II,因此,他最好的行动是与这一现实相一致。这意味着乙将要选择第2列。否则的话,他将失去每一次游戏,而选第2列乙则将赢得每场游戏。这个游戏对甲而言肯定是不公平的,但理性的竞赛需要玩家按指示办事。毕竟,甲很容易看到,如果乙每次都选第2列,然后选行II将导致每次亏损5元,而选行I则每次损失2元。这些数字可以被认为构成这个游戏的一个“解”。
上面的分析是从甲的角度看开始的,并表明有一个主导的行。我们也可以从乙的观点开始分析。事实表明,从乙的角度来看第2列是主导列。为什么无论甲选什么,乙选第2列会产生更高的回报?从逻辑推理的角度来看,在理性的发挥造成这样的结果这个意义上,把行I和第2列的结果称为游戏的“解”似乎是合理的。(对于更复杂的博弈论的情形下,游戏可能有一个以上的“解”。其原因是,以不同的方式观察合理或理性的行为寻找导致不同观点下的不同结果。)
在以最佳方式玩图3中的游戏时,每个玩家能够选择一行和一列,以便得到他和她最好的结局。此言为真这一事实可以表述为:有一个“纯”的策略(甲总选一个固定的行而乙总取一个固定的列)可导致最佳结果。这个术语对游戏是否玩一次或多次都可用,也适用于游戏是否是零和的。请注意,情况并不总是这么“利落”的。对于有些游戏,不存在涉及“纯”策略的最佳对阵方式。
现在考虑一个不是零和的游戏(图4)。
| 乙 1 | 乙 2 | |
|---|---|---|
| 甲 I | (2, 1) | (3, 0) |
| 甲 II | (4, -5) | (1, 2) |
假设甲和乙已经愉快地玩了几个回合这个游戏。甲和乙都得到积极的回报,虽然乙没有甲得到的回报多,他对其回报为1绝非沮丧。现在,甲注意到,如果乙在接下来的一轮中继续选第1列,她会得到4(而不是1)个单位的回报,且乙的回报则是-5。甲不是真的不喜欢乙,但她思忖道,他在前面几轮已经赢了一些钱,现在可以承受一点损失而不会太生气。因此,在下一轮中甲取行II,而乙选第1列。不用说乙对甲从行I改为行II感到不快,但他注意到,如果甲计划假设乙是一个下一轮还选第1列的“易受骗者”,则她没想法就有问题了。乙意识到,如果甲玩行II,则他将在下一轮中以第2列对应。这不仅将抹去他的损失,而且当玩的是行I和第1列时他会比甲赚得更多。此外,如果当他移到第2列时甲移到行I,他将比目前失去5元的情况有更好的回报。假设甲保持在行II且乙移动到第2列。现在,甲没有她刚才得到回报2元而她的对手只有1元收益那样高兴,做出决定:如果乙继续玩第2列,她就想移到行I。好,你得到想法了。这个游戏没有结果,其中两名选手之一可能不被诱惑到另一个动作。没有“纯”的行动会导致游戏的一个“解”。
现在,让我们回到零和的情形。考虑下面的游戏(图5):
| 乙 1 | 乙 2 | |
|---|---|---|
| 甲 I | (1, -1) | (-1, 1) |
| 甲 II | (-1, 1) | (1,-1) |
这个游戏在回报上是对称的,但它不具有任何主导其他行或列的行或列。甲和乙各自四个回报的数目之和为0。该游戏是公平的,即无论哪个玩家玩这个游戏许多次后,其长期回报将是0。(要求得长期回报,把个人经过所有游戏的赢钱加在一起再除以游戏的次数。)这确实是一场公平的游戏,但是这并不意味着可以用随意方式玩它。因此,假设甲决定,为使自己玩得更轻松,她将以固定的次序I,I,II,I,II,II,一遍又一遍地重复选择。过了一段时间后,细心的玩家乙就会发现这种模式,并开始玩第2,2,1,2,1,1列的重复次序,结果他将赢得每场游戏。当然,甲可能发觉自己总是输钱的事实,所以聪明的乙通过看到对手的一个确定模式而改变自己的策略,使他赢得大部分而不是所有的游戏!
可能不是预期的一点是,玩这个游戏的人,比方说甲,需要使用一点行的随机模式。这不是行的任何随机模式,而是某种随机模式,使得1/2的时间选行I,1/2的时间选行II。玩游戏的这个方式被称为最优混合策略。“混合”是指甲选各行的时间是混合的或部分性的(这对乙也类似)。为了得到最好的回报,甲绝不能以确定性的模式选行,而必须以混合比例的某个特殊时间方式选行I和行II。在随后的游戏(图6)中,如何找到玩家的最优混合策略?
| 乙 1 | 乙 2 | |
|---|---|---|
| 甲 I | (8, -8) | (-6, 6) |
| 甲 II | (-2, 2) | (3,-3) |
我们不从头开始推导相应的定理,而是显示使用这些结果之一的某种方法,以缩短计算类似这个游戏的混合策略。值得注意的是,已被证明,对于许多如同下面例子的2人零和游戏,当一个玩家,比方说甲,玩其最优混合策略导致长期回报P,这与其他玩家用什么模式没有什么区别;其他玩家的收益将是-P。注意甲以最佳方式玩游戏并不保证她的最佳长远回报将是正的。
使用这个定理,我们可以计算出图6游戏中每个玩家都应该玩的最佳混合方式。举个例子,我们用p代表甲实现自己最大回报选行I的那部分时间。那么她应该花1-p的时间选行II。因为在这种情况下,无论乙怎么玩,甲的回报都是相同的,让我们先计算当乙所有时间都取第1列时甲的回报。
由于甲以p的时间玩行I,其长期回报的“期望值”是8p;由于她花1-p的时间用行II,对应的期望回报则是-2(1-p)。从长远来看,这种模式得到的回报是8p-2(1-p)。当乙总使用第2列时,类似的计算给出回报-6(p)+(1-p)。因此,为了找到最佳的p值,我们必须求解以下关于p的线性方程:
它的解是p=5/19。容易看到乙选用第1列应花的时间为q=9/19,但值得通过求解线性方程计算之来进行一次思维练习。
要找出谁具有优势,可将p=5/19代入到上面方程中的左端或右端。我们看到甲的回报是12/19,因此,乙的回报是-12/19。没有数学,这不是一个容易看到的数!因此,如果这场比赛重复19次,甲的回报则大约为12元。游戏每玩一次,8元、6元、3元或2元易手,但经过多次游戏后平均下来,甲每次会赢1元的12/19,而乙将失去1元的12/19。
冯·诺伊曼的一个著名定理指出,对于有两个玩家的零和游戏,每玩一次玩家甲有m个选择而玩家乙有n个选择,则游戏中每个玩家均有最优混合策略。这一最优策略有以下的性质:如果任一玩家偏离最佳的混合策略,那么该玩家只会更糟。
纳什均衡
然而,许多数学家和在现实世界中尝试运用博弈论的人须要分析的最有趣的游戏不是零和的。例如,下面的游戏可能是前面所述的一对夫妇试图决定是否要去看电影或歌剧这一情况的数学模型。
| 乙 1(歌剧) | 乙 2(电影) | |
|---|---|---|
| 甲 I(歌剧) | (6, 2) | (4, 4) |
| 甲 II(电影) | (7, 4) | (10, 3) |
运用主导策略分析得知,这个游戏的“解”是甲选行II而乙取第1列,并采用纯策略。然而,其他非零和游戏,如我们在图4中所看到的,没有纯策略的解。值得注意的是,已被证明,如果移动到一个“混合策略”的区域,甲和乙总是会有一个“平衡”的解———总存在一个“纳什均衡”。这个概念以约翰·纳什的名字命名,他在其开创性工作中证明了“平衡点”的存在性而赢得了诺贝尔经济学奖。纳什的定理是一个存在性定理。

他用数学上的Kakutani不动点定理证明了某些游戏的均衡点存在,但并没有说明如何找到它们。事实上,确定纳什均衡点的个数及其探讨计算复杂性的问题,仍然是一个活跃的研究领域。纳什均衡概念背后的基本想法是:对广泛的游戏类,能为玩家找到玩游戏的方式,它们有时为纯策略,有时是混合策略,因此如果一个玩家偏离纳什均衡策略,则不能改善其回报。我们对每个玩家有两种选择的二人零和游戏的详细分析提供了问题所涉及到的基本思想。
虚构的发挥
有数学技能的人可以完全掌握找到最佳游戏发挥的技术,如我们上面已看到的那些。但是,如果有一个更务实的方法玩游戏,如我们已解决了的图6那个,将更好。数学家朱莉娅·罗宾逊(1918-1985)得到这样的一个洞察,她最著名的研究是关于著名的希尔伯特第十问题的解。罗宾逊也是美国数学会的第一任女会长。她基于普林斯顿大学数学家乔治·威廉·布朗的想法,证明了一个耐人寻味的结果。布朗提出“虚构发挥”的想法,但该术语不甚贴切,因为它是一种往往在实践中可以使用的玩游戏的技术。

假设你正在玩一场零和游戏,没有主导的行或列,例如图6的那个。如果你已经掌握了如何玩的技术,则可以找到最佳方式来玩它。然而,另一种处理可能是,看看是否有一些“自适应”的方式玩游戏。直观地说,这个想法是在玩游戏中学习提高,以便玩得更好。你以一个你觉得不错的行动开始,根据对手的选择看你得到什么回报,然后试图“改善”你的状况。朱莉娅·罗宾逊证明:对于2人零和游戏,这种“从战争中学习战争”的方式是有效的。最后,如果每个玩家采用这个观念,他们最终会收敛到其最佳混合策略。不幸的是,如2012年诺贝尔经济学奖得主夏普利(Lloyd Shapley)所证,这不是对所有游戏都对。夏普利则提供了一个3×3的游戏例子,对此自适应学习方法不起作用。罗宾逊的工作及其扩展与称为动力系统的数学分支有着重要联系。她的工作已由不同的方式被扩展。别的工作已经显示出玩游戏的自适应方法与一般学习环境的想法之间的连接。目前研究人员还在揭示与进化生物学的想法的令人兴奋的联系,其中博弈论具有激动人心的影响。
囚徒困境
也许所有的游戏中,最有名的是囚徒困境,值得大书特书。这个游戏的名字来自阿尔伯特·塔克的一个游戏伴随矩阵的“故事”,塔克曾是普林斯顿大学数学系多年的系主任。故事有助于解释二人非零和博弈的回报,其结构具有“似是而非”的影响。
 阿尔伯特·塔克
阿尔伯特·塔克 下面是属于囚徒困境类型的游戏。
| 乙 1(歌剧) | 乙 2(电影) | |
|---|---|---|
| 甲 I(歌剧) | (3, 3) | (0, 5) |
| 甲 II(电影) | (5, 0) | (1, 1) |
如果进行这个游戏的主导战略分析,我们看到玩家应该玩行II和第2列,以实现他们“最好”的结果。然而,这时甲和乙各自的回报1比他们分别取行I和第1列各自的回报3要小。这就造成了自相矛盾的情况:合理的玩比不合理的玩导致较差的结果。当结果为负时,这种情况更为显著。
| 乙 1(歌剧) | 乙 2(电影) | |
|---|---|---|
| 甲 I(歌剧) | (8, 8) | (-6, 20) |
| 甲 II(电影) | (20, -6) | (-4,-4) |
博弈理论认为,当玩一次这个游戏或重复玩时,“理性”的方式是选行II和第2列。可是,如果有每次对局不是失去4个单位,而是分别获得8个单位这样一个结果出现,这似乎难以接受。但是,博弈论的分析表明,选行I和第1列不是“稳定”的。玩家以这个方式反复玩这个游戏时,总会被这样的事实诱惑:如果他们的对手不同步转移行动,那么他们可以提高自己的回报,而“伤害”他们的对手。因此,如果乙继续玩第1列,而甲从行I移动到行II,其结果将是,甲赚取20,而不是8,而乙则从赢8变到输6。不,这是真实的,即使甲和乙可能已经签署了“具有约束力的条约”。不幸的是,囚徒困境不只是一种对知识的好奇心。这似乎是各种对抗性游戏的一个合理模型,如工会和资方的合同谈判及国与国之间的关系。事实上,美国国防部为了试图理解与苏联的“冷战”政治带来的影响,对“实际的人们”面临囚徒困境之类的博弈时的行为做了认真研究。
蜈蚣博弈
相比囚徒困境,蜈蚣博弈不是众所周知的,但和囚徒困境一样,它对洞察理性的本质一直提供着非常肥沃的窗口。用博弈论的方式来进行蜈蚣博弈的理论预测与实际使用中所发生的现象之间的差异,创造了一个新的研究方向。
和囚徒困境相似的是,蜈蚣博弈实际上是有类似特征的一系列游戏,但特定的游戏变种依赖于一族数值参数。试验中使用不同的参数,产生不同的结果,以得到对这一族博弈的洞见。
这种游戏由一位数学训练有素的经济学家Robert W. Rosenthal所发展。然而,游戏的名字却属于Kenneth Binmore。
 波士顿大学的兰德尔·埃利斯教授
波士顿大学的兰德尔·埃利斯教授 不幸的是,Rosenthal57岁英年早逝在2002年死于心脏病。他的研究范围遍历博弈论和经济学之间相互作用的许多方面。他的工作经常涉及在经济设置中什么是合理或理性的行为这一问题。
蜈蚣博弈的基本思想涉及到游戏中两名玩家的交替移动,这被一种“扩展型”的树所描述。玩家从当前的移动及其对手可能的下个举动来看,目前的结果给了自己比对手更多的回报,但下次的移动会有相反的结果。下面是该游戏的一个通用版本。两个玩家的名字分别是A和B,在“决定树”的一个给定顶点(小白圈),玩家的名字交替着。在一个特定的点,比如说标有A的那个,在这里玩家A有两种走法可选,必须作出决定。A可以移动到右侧(到右边的一个顶点),让B决定下一步该怎么做,或向下移动,终止游戏。在蜈蚣博弈的文献中,向右走通常被描述为“通过”,这意味着玩家将不会终止游戏(除了最后的决策以外),而向下走的决策则被形容为“拿”。向下箭头端部的的两个数字是A的回报(左边)和B的回报(右边)。向下移动(拿)以蓝色显示,以便与向右移动(通过)相对照。通常假定游戏中A和B对移动所做的决策数目相等。(这意味着树中的1价顶点或叶的个数为奇数。)
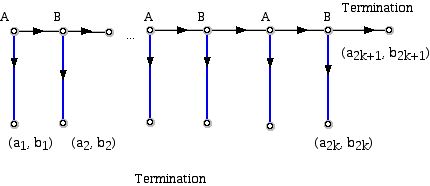 图10
图10 该游戏从上面的图中得到它的名字,因为此图与一个有许多条腿的小动物相似。不过,考虑一下图11所示的蜈蚣博弈的一个小型版本,从中能看到这个游戏在理论家眼里的麻烦之处。
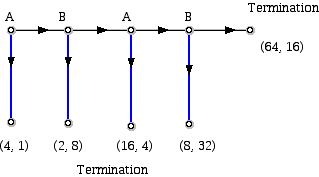 图11
图11 假定你是A。你会怎么玩这个游戏?这里是伴随着把该游戏视为具有完善信息的数学推理,当中此游戏的双方玩家是完全理性的,且每个对手的行为也理性的。假设游戏达到这个阶段,此时玩家B必须在最右边的决策顶点采取行动。想多挣钱的B会在此节点选择“拿”(向下)。这样做是因为如果B选“通过”,他的回报是16,而他的对手却得到64。通过“拿”,B得到32,而A只有8。因此,在之前的顶点,由于A知道B会做什么,会选择“拿”(下)。认识到这一点,“反向推理”是指在之前的节点B将取的行动,这反过来又意味着,在第一个的决策顶点,A也应该做的!这种类型的推理已经被称为“逆向归纳”。同样,在蜈蚣博弈的“长”版本(例如,许多英尺长)中,这意味着A在玩游戏第一步时应选择“拿”(向下)。这意味着,双方玩家获得相对微薄的回报。玩更长时间的游戏给每个玩家提供了一个赢得更多的机会,但伴有一旦停止游戏,自己的对手将比自己获得更多的回报这一风险。
在这个变型的游戏中,每个玩家得到的金额将迅速增加,然而,在游戏的另一些变种中,则增长得非常缓慢。这些游戏的特点是,合理的发挥表明,第一个玩家开始时应采取正确的步骤。然而,这似乎是一个令人困惑的的选择,因为通过“非理性”可以得到这么多。另外,请注意,如果在游戏的第一个节点A通过(允许B移动),然后B面临着蜈蚣博弈的一个新版本,它本质上和A的刚才那个有相同的结构!如果你是玩家A,你为什么不采取第一个机会?原因之一是,你的个性中可能有一些“利他主义”的成分。你可能也会想,如果蜈蚣更长(而不是只有四条腿),也许你的对手将犯一个错误的分析,做出他(她)继续长玩的决定。
如果把这个游戏给真实的玩家(而不是哲学家、数学家和博弈理论家)玩时,看看会发生什么则变得非常有趣!实验经济学家和其他学者实际上已经做到了这一点。被解释清楚游戏规则并充分理解的真实的玩家在第一步几乎总是不终止游戏!这是否意味着我们对游戏的分析是错误的,或人类是“不理性”的?
很多人在“给定第一轮上场机会时不选择‘拿’”这个不“理性”地玩这个游戏,你感到惊讶吗?另一方面,也有这种情况,游戏通常没有只要允许在最后一个顶点B选取“通过”进行到最后。蜈蚣博弈的变形提供了处理利他主义本质、实现合作信号以及理性限制的一个受控环境。这些试验工作在广泛的形式上和蜈蚣博弈相结合,并从最近使用正常的蜈蚣博弈的工作中得到了新的洞见。在这项工作中,试验主题必须命名“圆”,在那里他们将在蜈蚣博弈中“拿”,而不是动态地玩游戏。最近一组有趣的试验涉及玩家群体在蜈蚣博弈中竞争,而不是个人互相打斗。结果表明,与个人比赛相比,群体在游戏的第一轮更接近采取“拿”的预测。来自蜈蚣博弈灵感的理论型和试验型的论文越来越多,这是这一单一学科生育力旺盛的例证,这个学科的思想刺激的不只是数学家,还有各行各业的学者们。