信息时代的图论
译自:Notices of the AMS, Vol.57 (2010), No.6, p.726-732, Graph Theory in the Information Age, Fan Chung, figure number I. Copyright ©2010 the American Mathematical Society. Reprinted with permission. All rights reserved. 美国数学会与作者授予译文出版许可。译文经作者审定。
近 10 年来,图论经历了剧烈而深远的演变。这演变的主因是由于巨量数据和信息的需求与冲击。目前处理巨量信息的主要方法是利用其中相互关联,先制成图(graph), 然后加以分析和运用。例如,谷歌 (Google) 的网络搜索算法关键是靠着引用万维网(www)图,它以所有网页为顶点,以超链为边。有各种各样的信息网络,既有由生物数据库构成的生物网络,又有电子邮件、电话、短信组成的社会网络,以及各种类型的物理网络。数学家特别感兴趣的是基于《数学评论(Mathematical Reviews)》数据的所谓合作图(collaboration graph):每个数学家是该图的一个顶点,当两位数学家有共同一篇论文以边相连。
图 1 是合作图中子图,它包含 Erdős (爱尔迪希)数是 2 的总共约 5000 多位数学家的顶点所导出的子图(所谓爱尔迪希数是 2 的数学家,就是与爱尔迪希数是 1 的数学家共同署名发表过论文者,而爱尔迪希数是 1 的数学家则是与爱尔迪希共同署名发表过论文者。)
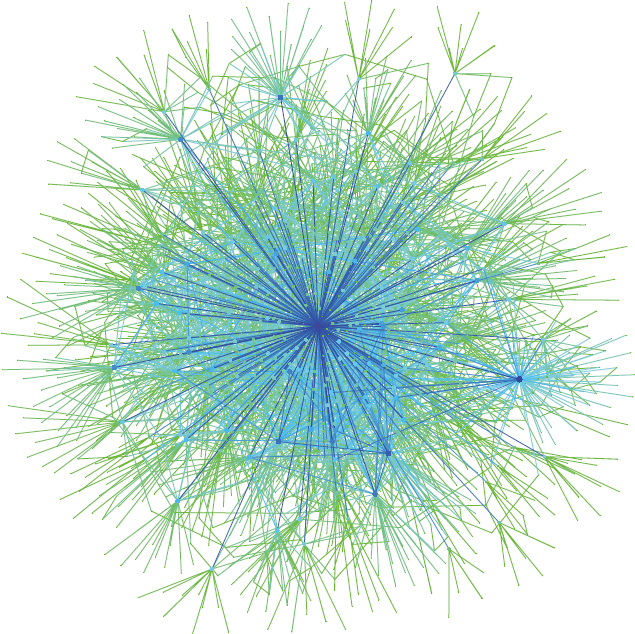 图 1 合作图的一个诱导子图
图 1 合作图的一个诱导子图
图论已有 200 余年历史,它是用来研究有关图(graph)的基本数学结构。一个图 $G$ 由一组顶点 $V$ 和一组边 $E$ 组成,每条边连接一对顶点。图论一直有广泛的应用,然而在理论和应用上我们不曾碰到庞大且复杂的图。很多挑战性问题吸引了许多研究者,他们来自于物理学、计算机科学、工程、生物学、社会科学和数学领域。“网络科学”这一新领域脱颖而出,它呼唤坚实的科学基础和严格的分析,而图论最适合于担当此任。此外,出于现实世界的图例也引导出了图论新的研究方向和主要问题。
这些出于实际的网络都巨大而复杂,但显现了令人惊奇的一致性。大多数现实世界的图具有下述共性:
稀疏性——边数不超过顶点数的常数倍。
“小世界现象”——任意两个顶点可用一条短路径相连。当两个顶点有公共邻点时,这两点很可能有边相连。
顶点度分布的幂律——一个顶点的度是它的邻点数。度为 $j$(或有 $j$ 个邻点)的顶点个数与 $j ^ { - \beta }$ 成正比,这里 $\beta$ 是某个正常数。
为处理这些信息网络而产生了很多基本问题:这类大规模网络的基本结构是什么?它们如何演化?是什么原理主宰它们的行为?这些大规模(并且常常是不完全的)母图与子图彼此关系如何?哪些图的不变扯掌控这些大图的众多性质?
为解答这些问题,我们首先运用已有的知识,尽管通常是不够的。在过去 30 年里,组合、概率及谱方法上都有了长足进展。但传统的概率方法大多考虑顶点或边具有相同概率分布,而现实世界的图却是参差不齐和分堆聚集的。经典的代数和分析方法足以处理高度对称的结构,而现实世界的图却并非如此。实际的图的研究激发我们拓荒、拓展和创造新的理论和方法。我们将讨论图论的几个正在快速发展论题。这些论题是:给定顶点度分布的随机图理论,一般图中的渗流 (percolation), 表达顶点间的相互关系的页秩 (PageRank)1, 以及图的对策方面。
对于一般度分布的随机图理论
随机图理论最早的研究对象是爱尔迪希和 Rényi (雷尼)在 1959 年引入的经典随机图 $G(n, p)$[38, 39](也由 Gilbert[44]独立地引入)。$G(n, p)$ 有 $n$ 个顶点,每对顶点有边相连的概率是 $p$。在一系列论文中,爱尔迪希和雷尼对 $p$ 增大时 $G(n, p)$ 的演化给出了优美且全面的分析。因为任何一个随机图 $G(n, p)$ 的每个顶点度的期望值相同,所以 $G(n, p)$ 没有把握住现实世界的图的某些主要特性。尽管如此,经典随机图理论的处理方法为研究一般度分布随机图提供了基础。
在研究信息网络图时提出了不少随机图模型,但基本上是两种不同的处理方法。一种是模仿一个动态网络成长和衰落的“在线”模型,另一种是由特定图族作为某种特定概率分布的概率空间构成的随机图的“离线”模型。
一种称作偏好连接方案 (perferential attachment scheme) 的在线模型可以说是“富者更富”,近年来在研究复杂网络时这种模型颇受关注[11, 57], 但它的历史起码可以追溯到 1896 年(意大利经济学家)Vilfredo Pareto 的工作。这个方案就是在时钟的每一次滴答声中,在每个顶点处以正比于其顶点度的概率添加一条边。可以证明这个模型有着幂律的度分布[1 5, 31, 57]。还有几种别的在线模型,其中有复制模型(它似乎更适合于生物网 络,见[35]) 以及很多其它的推广模型,比如,加入每个顶点的“才能”或“适应性”的参数[50]。
对于一般度随机图有两种主要的离线模型——构形 (configuration) 模型和期望度模型。在度序列为 $d _ { 1 } , d _ { 2 } , \ldots , d _ { n }$ 的构形模型中,一个随机图定义如下:在一共 $m = \sum _ { i = 1 } ^ { n } d _ { i }$ 个“虚节点” 上取一随机匹配,这些虚节点被分成大小为 $d _ { i } ( i = 1,2 , \ldots , n )$ 的 $n$ 部分,每个部分结合一个顶点,利用 Molloy 和 Reed 的结果[58, 59]可以证明[2], 在某些条件下,形成指数 $\beta$ 的一个随机幂律图。当 $\beta \geq \beta _ { 0 }$ 时几乎不会有巨分支,这里 $\beta _ { 0 }$ 是涉及 Riemann (黎曼)$\zeta$ 函数的方程 $\zeta ( \beta - 2 ) - 2 \zeta ( \beta - 1 ) = 0$ 的一个解。
在期望度模型中,期望度序列是 $\mathbf { w } = \left( w _ { 1 } , w _ { 2 } , \dots , w _ { n } \right)$ 的形成随机图 $G(\mathbf { w })$ 承袭了爱尔迪希–雷尼模型的精神。第 $i$ 与第 $j$ 个顶点有边相连的概率定义为 $w _ { i } w _ { j } / \mathrm { Vol } ( G )$, 这里 $ \mathrm { Vol }(G)$ 表示 $\sum _ { i } w _ { i }$。 此外,$G(\mathbf { w })$ 的各条边独立选取,从而便于分析。如果 $G(\mathbf { w })$ 的期望平均度大于 $1$, 则它有巨分支 ([28]) (即,体积是全图体积的正分数的连通分支),而且巨分支的体积是 $\delta \mathrm { Vol } ( G ) + O \left( \sqrt { n } \log ^ { 3.5 } n \right)$, 这里 $\delta$ 是下列方程 $$\sum _ { i = 1 } ^ { n } w _ { i } e ^ { - w _ { i } \delta } = ( 1 - \delta ) \sum _ { i = 1 } ^ { n } w _ { i }\tag{1}$$ 的唯一非零根[29]。因 $G(\mathbf { w })$ 模型充满活力,可以导出许多图的结构和性质。例如,只要 $w$ 满足一些条件,随机图 $G(\mathbf { w })$ 的平均距离几乎肯定等于 $( 1 + o ( 1 ) ) \frac { \log n } { \log \tilde { w } }$,直径几乎肯定是 $\Theta \left( \frac { \log n } { \log \tilde { w } } \right)$,其中 $\tilde { w } = \sum _ { i } w _ { i } ^ { 2 } / \sum _ { i } w _ { i }$[27]。多数实际网络中幂律的指数 $\beta$ 满足 $2 < \beta < 3$,这时的幂律图可以描述成“章鱼”状,其主体是具有小直径 $O ( \log \log n )$ 的稠密子图,而全图的直径是 $O ( \log n )$, 平均距离是 $O ( \log \log n )$[31]。
关于幂律图的谱,基本上有两种思路争雄。一种是去证明 Wigner (威格纳)半圆律的类似结论,另一种预测特征值服从幂律分布[40]。虽然半圆律和幂律的说法很不一样,但如果考察与图相关的适当矩阵, 则两个断言本质上都是正确的[33, 34]。在 $\beta > 2.5$ 时,一个幂律随机图的邻接矩阵的最大特征值几乎肯定是 $( 1 + o ( 1 ) ) \sqrt { m }$,这里 $m$ 是最大度。而且如果 $k$ 充分大,$k$ 具有依赖于 $\beta , m$ 和 $w$ 的函数上界时,最大的 $k$ 个特征值有指数 $2 \beta - 1$ 的幂律分布。在 $2 < \beta < 2.5$ 时,最大特征值集中于 $c m ^ { 3 - \beta }$,其中常数 $c$ 依赖于 $\beta$ 和平均度。此外,当最小的期望度相对较大时,(规范化)Laplacian (拉普拉斯)阵的特征值服从半圆律[34]。
在线模型显然远比离线模型来得复杂而难以分析。一种可能的处理方式是把具有相似度分布在线随机图和离线模型联系起来。如果找到合适的条件, 在线模型可在某种误差范围内被夹在两个离线模型之间。这时,我们可用离线模型的方法来预测在线模型的性质[30]。
给定母图中的随机子图
我们注意到的几乎所有信息网络都是某些庞大而且信息不全的母图的子图。一个主要的问题是试图从母图导出它的一个随机子图的性质,以及反方向的从子图导出母图的性质。探究一个图和它的子图的关系是一个重要的问题。母图的哪些不变蜇可以遗传到它的子图?在哪些条件下我们可以预测所有或者任一子图的性质?一个稀疏子图会不会具有与其母图大相径庭的性质?我们在此讨论这个方向上的一些工作。
正如所谓的“小世界现象”所指明的那样,很多信息网络或社会网络的直径很小(约在 $\log n$ 范围内)。然而,Liben-Nowell 和 Kleinberg 的一篇近期论文[52]提到,从某些链 字母数据 (chain-letter data) 导出的树状子图似乎有相对较大的直径。对爱尔迪希-雷尼图模型 $G(n, p)$ 的研究表明,一棵随机支撑树的直径的阶是 $\sqrt { n }$, 而其母图 $K_n$ 的直径是 $1$[60]。Aldous[4]证明,对于谱具有一定上界 $\sigma$ 的正则图 $G$ 来说,它的一棵随机支撑树 $T$ 的直径 $diam(T)$ 的期望值满足
$$\frac { c \sigma \sqrt { n } } { \log n } \leq E ( diam ( T ) ) \leq \frac { c \sqrt { n } \log n } { \sqrt { \sigma } },$$其中 $c$ 是某个绝对常数。在[32]中 证明了,对于一般的母图 $G$, 它的一棵随机支撑树的直径以很高的概率在 $c \sqrt { n }$ 和 $c ^ { \prime } \sqrt { n } \log n$ 之间,其中 $c$ 和 $c ^ { \prime }$ 依赖于 $G$ 的谱隙(spectral gap)。以及 $G$ 的度序列的矩量之比。
处理给定母图 $G$ 的随机子图的一种做法,是把它当作一个(接合)渗流 ((bond) per-colation) 问题。对正数 $p \leq 1$, 我们考虑在 $G$ 中独立地以概率 $p$ 保留每一边和以概率 $1 - p$ 删去每一边的 $G_p$。一个有意义的基本问题是:决定 $G_p$ 含有巨分支的临界概率 $p$。在流行病学的应用中,我们所考察的一般母图是接触图 (contact graph), 其中两个人若可能接触则以边相连。这时决定临界概率就相应于找到疾病流行的阈值。
渗流问题早就在理论物理学中有很多研究,尤其当母图是格图 $\mathbb { Z } ^ { k }$ 时[45, 49]。在格图上的渗流问题以困难著称,即使对低维时也才刚刚解决了所谓的靴带 (boot strap) 渗流[8, 9]。有许多在特殊母图上的渗流问题的研究成果。Ajtai, Komlós 和 Szemerédi (斯泽梅雷迪)研究了超立方图上的渗流问题[3], 他们的工作后来被推广到 Cayley (凯莱)图[1 6, 17, 18, 55]和正则图[42]。对于度不大于 $d$ 的扩张子 (expander) 图,Alon, Benjamini 和 Stacey 证明了渗流阈值不小于 $1 / 2 d$[5]。在其他方面,Bollobás,Borgs, Chayes, 和 Riordan 证明了(度的阶是 $\Theta ( n )$ 的)稠密图的巨分支阈值是 1$/ \rho$, 这里 $\rho$ 是邻接矩阵的最大特征值[13]。以完全图 $K_n$ 为母图的特定情况与爱尔迪希–雷尼图有关,已知后者的临界概率是 $1/n$, 以及“相变 (double jump)” 接近阈值。
对于一般的母图,渗流问题的答案难以捉摸。提出此问题的一种方式是寻找母图的适当条件,使得渗流可以被控制。已在 2009 年证明[26], 如果母图满足依赖于谱隙和度序列的高阶矩的一些条件,则对任一 $\epsilon > 0$,由 $p > ( 1 + \epsilon ) / \tilde { d }$ 几乎肯定可知渗流的子图 $G_p$ 有巨分支;另一方面,由 $p < ( 1 - \epsilon ) / \tilde { d }$ 几乎肯定可知 $G_p$ 不含巨分支,其中 $\tilde { d }$ 是二阶平均度 $\tilde { d } = \sum _ { v } d _ { v } ^ { 2 } / \sum _ { v } d _ { v }$,$d _ { v }$ 是顶点 $v$ 的度。
一般情况下,子图与其母图的谱隙可以很不同。但是,如果图 $G$ 的(规范化)拉普拉斯阵的非平凡特征值与 $1$ 的距离不超过 $\sigma$, 则可以证明,随机子图 $G_p$ 的非平凡特征值当度不太小时几乎肯定属于同一范围(不计低阶量)[25]。
页秩和局部划分
图论中有很多的几何概念,像距离(它是从一个顶点到另一顶点所经的边数)、割(cut, 即把图的一部分与其余部分分割开的所使用的顶点集或边集)、流(flow, 即连接给定顶点间的途经)等等。然而,现实世界的图展示了“小世界现象”,即任意一对顶点可用一条很短的路相连接,于是通常的图距离概念不再很有用。我们需要用精确定量和表达来区别顶点间的"局部”或者”总体”、“类似”或者“不相似”之间差异。这正是页秩的重要概念。
S. Brin 和 L. Page 在 1998 年为谷歌的网上搜索算法引入页秩概念[19]与原先在数据检索时常用的模式匹配方法大不相同,页秩的创新在于完全依据网图 (underlying Web graph) 来确定一个网页的”重要性”。虽然页秩本来是为网图设计的,但这个概念和定义对任何图也行之有效。事实上,页秩已成为在任一给定图上检验顶点对(或子集对)之间相互关联的有效工具,并因此导致在图论上的应用。
页秩的起始点是对于边 $u$,$v$ 具有边赋权 $w_{u,v}$ 的图 $G$ 上的一个通常的随机游动。概率转移阵 $P$ 定义为 $P(u,v)=w_{uv}/d_u$, 其中 $P(u,v)= w_{uv}/d_{u}$ 对于一个偏好向量(preference vector)$s$ 和跳跃常数$a > 0$, 用 $\operatorname { pr }(a,s)$ 表示的页秩,作为一个行向量,可以如下地表示为随机游动的级数形式:2
$$\operatorname { pr } ( \alpha , s ) = \alpha \sum _ { k = 0 } ^ { \infty } ( 1 - \alpha ) ^ { k } s P ^ { k }.\tag{2}$$同时,$\operatorname { pr }(a,s)$ 满足下列递推关系:
$$\operatorname { pr } ( \alpha , s ) = \alpha s + ( 1 - \alpha ) \operatorname { pr } ( \alpha , s ) P.\tag{3}$$在 Brin 和 Page 的原始定义中[19], $s$ 是在每个顶点处取值 $1/n$ 的常数函数,它源自一位典型冲浪者行为的模型:冲浪者以概率 $\alpha$ 从一个网页随机转移到另一网页,而以概率 $1 - a$ 从一个网页转移到本页上有超链接的网页因为页秩和随机游动的密切联系,所以有快速有效又可靠的算法来计算近似页秩[6, 12, 47]。这引出了很多应用,其中包括如何在图中找到一个“好"割这样的基本问题。对于在图中把顶点子集 $S$ 分离出来的割,它“好”的程度可用下面的 Cheeger 比 $h(S)$ 定量地来度量:
$$h ( S ) = \frac { | E ( S , \overline { S } ) | } { \operatorname { Vol } ( S ) },$$其中 $E ( S , \overline { S } )$ 是一个端点属于 $S$ 另一端点不属于 $S$ 的所有边的边集,而 $\mathrm { Vol } ( S ) \leq \mathrm { Vol } ( G ) / 2$ 图 $G$ 的Cheeger 常数 $h_G$ 如是对所有满足 $\mathrm { Vol } ( S ) \leq \mathrm { Vol } ( G ) / 2$ 的顶点子集 $S$ 的最小 Cheeger 比 $h(S)$。算法设计中传统的分离和控制策略依赖于找到一个具有小 Cheeger 比的割。因为找出其 Cheeger 比等于 Cheeger 常数的割是 NP 困难问题[43]。使用最广泛的一种近似算法是谱划分算法 (a spectral partitioning algorithm)。利用特征向量将顶点排列,谱划分算法可以把要考察的割数从指数级约化为线性级选择。然而这种化简的算法仍有如下的性能保证,这个由 Cheeger 不等式
$$2 h _ { G } \geq \lambda \geq \frac { h _ { f } ^ { 2 } } { 2 } \geq \frac { h _ { G } ^ { 2 } } { 2 }$$来提供,其中 $f$ 是与谱隙 $\lambda$ 相关的特征蜇,而 $h _ { f }$ 是由 $f$ 所决定的顶点排列的次序开始一段的顶点子集的 Cheeger 比的最小值对于具有数以上亿的顶点的巨图来说,计算特征向扯并不可行。此外,所需要的则是所谓的局部割:对给定的种子 (seed) 和给定的大小,想找的是种子附近分离出指定大小的割。再者,找到这样的割的成本或复杂度将会与分离部分的大小成正比,而与全图的大小无关。这样一来,页 秩起作用了。2004 年,Spielman 和 Teng[63] 把 Lovász 和 Simonovitz 的一个混合结果[54](也见[56]) 用于随机游动及其性质分析而引入局部划分算法。而有一个改进的划分算法[6], 其性能保证可由下列局部 Cheeger 的不等式
$$h _ { S } \geq \lambda S \geq \frac { h _ { g } ^ { 2 } } { 8 \log \operatorname { Vol } ( S ) } \geq \frac { h _ { S } ^ { 2 } } { 8 \log \operatorname { Vol } ( S ) }$$来导出,其中 $\lambda _ { S }$ 是 $S$ 所导出子图的 Dirichlet 特征值,$h _ { S } = \min _ { T \subseteq S } h ( T )$ 定义为 $S$ 的局部 Cheeger 常数,而 $h_g$ 是当种子作为 $S$ 的一个顶点,而 $\alpha$ 是适当选取的仅与 $S$ 的体积有关时的所有页秩 $g$ 的最小 Cheeger 比。因导出满足上述局部 Cheeger 不等式的 Cheeger 比的页秩的种子集相当大(约 $S$ 体积的一半),利用这个事实,这个近似的划分算法还可以进一步改进。我们注意到,局部划分算法还可用作找到对整个图来说的平衡割 (balanced cut) 的一个子程序。
注意到在 (2) 式中页秩表示为随机游动的几何(级数),和这可用考察随机游动的指数和来取代,它称为热核页秩 (heat kernel pagerank) , 它满足热方程。可以用来在局部 Cheeger 不等式的下界中去掉对数因子,因而热核页秩导致一个改进的局部 Cheeger 不等式[23, 24]很多图论问题可能从页秩及其变形得益,而这些思想的丰富内涵尚待探索。
网络对策
在早晨的车流中,每个去上班的人都选自己最合适的路而不顾对他人的影响。因特网可以看成是一个类似的大世界,其运作既无中央控制,也不受制于协调一致的规则。每一个体的基本动机只能溯源到贪心和利己主义, 他们选择各自最合适的途径和策略使可能的回报最大化。也就是说,为处理大网络的定量分析和算法设计,我们面对的都是对策论和图论的组合。很多问题因此而产生。我们关心的不再是 Nash(纳什)均衡的存在, 而是设计算法来有效地计算近似纳什均衡。这样的算法收敛速度有多快?在关于纳什均衡的计算复杂性方面最近已有很大的进展[22, 37]。
自私路由 选择的分析自然地出现在网络管理中。不协调路由选择对网络的诸如稳定、拥塞和延迟等性质有多大影响?如何来协调一些有限制的规则?所谓无政府状态的代价说的是估计由自私路由选择所造成的集体利益损失的最坏情况分析。对自私路由选择已有大量研究[62], 读者可参看综述论文[41, 51]和关于这个专题的近著[61]。
可以从对策论角度重新审视图论的很多经典问题。图论的一个流行论题是图染色理论。对一个给定的图 $G$ 的每个顶点染色,最少需要几种颜色才能使得相邻接顶点的染色不同?除理论兴趣外,图染色问题在协调有冲突的方案上有许多应用。例如,当每位教师(作为顶点)都想安排在有限几个教室(作为颜色)讲课时,如果两位教师在同一时间有课则相应的两顶点连边。于是教室排课问题可看成一个图染色问题。我们可以设想一种不同于有主管机构来作安排的对策论情景:教师们通过互相协商来得出一种不冲突的安排。假设一个参与者(顶点)的颜色不同于其所有邻点的颜色时会有一份报酬,于是一种正常染色就是一种纳什均衡,因为任何参与者都没有动机改变其策略。
Kearns 等[48]在某些特定网络上进行了几种染色对策的实验研究。对于在每个顶点处采取简单和自私的步骤,有许多例子说明了在分析它们的互动时困难。这须更多严格和准确的分析,特别是沿着最近 10 年发展起来的组合概率方法和广义鞅方法路线的分析[20]在这个方向上对图染色对策的多回合模型有一些结果[20], 但仍需更多努力。
总结
图论发展正处于一个新的征程,成为信息革命的核心一部分。自 Leonhart Euler 在 1736 年提出“哥尼斯堡七桥问题“以来,图论从最初的趣味数学发展到现今组合方法、概率方法和谱方法,它与其它数学和计算机科学的多种领域有深刻联系。本文提及图论中几个活跃的新方向。虽有不完备,但可看到其所涉及的丰富的数学内容以及其应用遍及当今技术的主线,许多有关领域还正在发展中,各种理论和应用的研究方向尚待有志者多加探讨。
参考文献(略)
注释:
1. 在计算机科学中,"PageRank" 常译成“网页排序”。因本文要把这个概念推广到一般图,故试译为"页秩"。译注
2. 原文将 (2) 左端误为 $\mathrm { pr } _ { \alpha , f }$。译注
| 作者: | Fan Chung(金芳蓉) |
| 译者: | 李乔,张晓东 |
| 校订: | 陆柱家 |
| 文章来源: |
Notices of the AMS, Vol.57 (2010), No.6, p.726-732, Graph Theory in the Information Age, Fan Chung, figure number I. |